Limitations of LLMs
A first clear example
While Large Language Models are powerful tools, they have significant limitations that users must understand to use them effectively and responsibly.
Consider this prompt and try to answer yourself:

This is the answer that an old version of ChatGPT gave:

ℹ️ This prompt was given to GPT 3.5, and newer versions improved in handling these examples. But the take home message remains!
Why is that?
Let’s focus on a key aspect: LLMs are trained on a vast amount of text. Including this common HR riddle:
Four people need to cross a rickety bridge at night. They have only one flashlight and the bridge can only hold two people at a time. The four people walk at different speeds: one can cross the bridge in 1 minute, another in 2 minutes, the third in 5 minutes, and the slowest in 10 minutes. When two people cross the bridge together, they must go at the slower person’s pace. The speed of two people crossing a bridge together is limited by the speed of the slower person.
![]() training data effect: imagine someone who has read a lot of puzzle books and is really good at remembering the answers. But if you slightly change the puzzle—or ask them to show their work—they might still give a “familiar” answer that doesn’t fit perfectly.
training data effect: imagine someone who has read a lot of puzzle books and is really good at remembering the answers. But if you slightly change the puzzle—or ask them to show their work—they might still give a “familiar” answer that doesn’t fit perfectly.
AI is everywhere
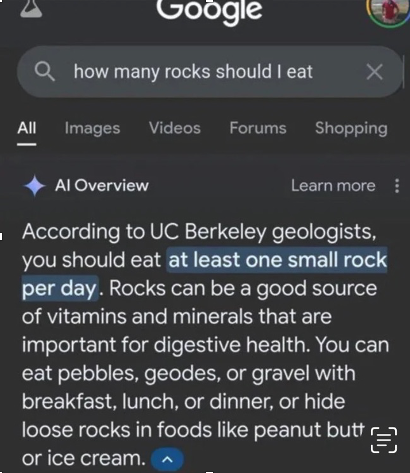
Google decided to incorporate an AI overview in their search engine. The training data used probably contains unreliable websites with satyrical or ironical answers given to legitimate questions, and this explains odd results.
This is not a problem if we use LLMs as tools, instead of considering them oracles with ready-to-use answers ![]() .
.
![]() Work in progress
Work in progress